HyperLogLog 应用场景
去重复统计功能的基数估计算法
算法知识前置
什么是UV?
Unique Visitor,独立访客,一般理解为客户端IP,需要去重考虑
什么是PV?
Page View,页面浏览量,不用去重
什么是DAU?
Daily Active User 日活跃用户量
什么是基数
是一种数据集,去重复后的真实个数
去重复统计的方式?
-
HashSet
-
bitmap: 如果数据显较大亿级统计,使用 bitmaps 同样会有这个问题。
bitmap 是通过用位 bit 数组来表示各元素是否出现,每个元素对应一位,所需的总内存为N个 bit 。 基数计数则将每一个元素对应到 bit 数组中的其中一位,比如 bit数组010010101(按照从零开始下标,有的就是1、4、6、8)。 新进入的元素只需要将已经有的 bit 数组和新加入的元素进行按位或计算就行。这个方式能大大减少内存占用且位操作迅速。 But,假设一个样本案例就是一亿个基数位值数据,一个样本就是一亿如果要统计1亿个数据的基数位值,大约需要内存100000000/8/1024/1024约等于12M,内存减少占用的效果显著。 这样得到统计一个对象样本的基数值需要12M。 如果统计10000个对象样本(1w个亿级),就需要117.1875G将近120G,可见使用 bitmaps 还是不适用大数据量下(亿级)的基数计数场景, 但是 bitmaps 方法是精确计算的
办法?
概率算法:
通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身, 通过一定的概率统计方法预估基数值,同时保证误差在一定范围内,由于又不储存数据故此可以大大节约内存。 HyperLogLog 就是一种概率算法的实现。
原理说明:
只是进行不重复的基数统计,不是集合也不保存数据,只记录数量而不是具体内容。 有误差,非精确统计,牺牲准确率来换取空间,误差仅仅只是0.81%左右
算法应用
网站首页亿级 UV 的 Redis 统计方案
hash
说明: redis—hash = <keyDay,<ip,1» 按照 ipv4 的结构来说明,每个 ipv4 的地址最多是15个字节(ip = “192.168.111.1”,最多xxx.xxx.xxx.xxx) 某一天的1.5亿 * 15个字节= 2G,一个月60G,redis 死定了。
HyperLogLog:
先看个场景:统计网站中每个页面的 UV,分每天,每周,每月。
由于 UV 和 PV 不同,UV 要去重,同一个用户每天点某个页面多次,也只算一次,所以可以用集合来存。每个页面加一个时间做一个key,里面存用户id。 如果网站流量非常大,则要占用非常多的内存。 为了这个小功能花费巨大的内存,未必划算。对于运营来说,某个页面200000的 UV 和 199838的 UV 区别不大,不需要绝对的精确。 这时我们就可以考虑使用 HyperLogLog 来储存。 HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%。 它的优点是效率高,省空间,真的很省。 HyperLogLog 提供了三个常用命令:pfadd,pfcount ,pfmerge。来实验下。
加10个用户:
127.0.0.1:6379> pfadd uv user1
(integer) 1
127.0.0.1:6379> pfadd uv user2
(integer) 1
127.0.0.1:6379> pfadd uv user3
(integer) 1
127.0.0.1:6379> pfadd uv user4
(integer) 1
127.0.0.1:6379> pfadd uv user5
(integer) 1
127.0.0.1:6379> pfadd uv user6
(integer) 1
127.0.0.1:6379> pfadd uv user7
(integer) 1
127.0.0.1:6379> pfadd uv user8
(integer) 1
127.0.0.1:6379> pfadd uv user9
(integer) 1
127.0.0.1:6379> pfadd uv user10
(integer) 1
统计下:
127.0.0.1:6379> pfcount uv
(integer) 10
增加另一个组:
127.0.0.1:6379> pfadd uv2 u1
(integer) 1
127.0.0.1:6379> pfadd uv2 u2
(integer) 1
127.0.0.1:6379> pfadd uv2 u3
(integer) 1
127.0.0.1:6379> pfadd uv2 u4
(integer) 1
127.0.0.1:6379> pfadd uv2 u5
(integer) 1
看下合并统计:
127.0.0.1:6379> pfmerge uv uv2 #把uv2的合并到uv
OK
127.0.0.1:6379> pfcount uv
(integer) 15
上面测试的是小数目,我们通过脚本批量导入20万条数据测试下:
import redis
import math
# 连接到Redis
client = redis.StrictRedis(host='localhost', port=6379, db=0, password='password')
# 清空HyperLogLog
client.delete('uv')
# 添加20万个数据
for i in range(200000):
client.pfadd("uv", "user%d" % i)
# 获取基数估算值
estimated_count = client.pfcount('uv')
actual_count = 200000
# 计算误差
error = abs(estimated_count - actual_count) / actual_count
# 计算理论误差率
b = 14
m = 2 ** b
theoretical_error_rate = 1.04 / math.sqrt(m)
print(f"实际基数: {actual_count}")
print(f"估算基数: {estimated_count}")
print(f"实际误差率: {error:.4%}")
print(f"理论误差率: {theoretical_error_rate:.4%}")
print(f"占用内存: {client.memory_usage('uv')}")
测试结果:
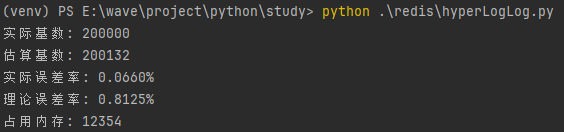
可以看到误差在0.81%,占用内存没超过12k。
我们测试下集合占用多少内存:
import redis
# 连接到Redis
client = redis.StrictRedis(host='localhost', port=6379, db=0, password='password')
# 清空HyperLogLog
client.delete('set_uv')
# 添加20万个数据
for i in range(200000):
client.lpush("set_uv", "user%d" % i)
print(f"集合占用内存: {client.memory_usage('set_uv')}")
测试结果:

差不多要1.8M了。 为什么redis的HyperLogLog这么省空间,有兴趣的可以看下走近源码:神奇的HyperLogLog
结语
HyperLogLog 是一个很强大算法,基于此我们可以又很多应用,我目前了解到的就是利用HyperLogLog实现去重复统计功能


...